基本入门算法有三个经典算法:冒泡,选择和插入算法
1.冒泡排序
冒泡排序重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
代码实现:
1 | # -*- coding:utf-8 -*- |
2.选择排序
从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
1 | # -*- coding:utf-8 -*- |
3.插入排序
每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。
步骤:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
代码实现:
1 | # -*- coding:utf-8 -*- |
4.希尔排序
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量
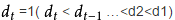
即所有记录放在同一组中进行直接插入排序为止。
1 | # -*- coding:utf-8 -*- |
5.归并排序
归并排序,就是把两个已经排列好的序列合并为一个序列。
代码实现:
1 | # -*- coding:utf-8 -*- |
6.快速排序
1 | 随意选择一个数字作为基准,比基准数字大的在右,比基准数字小的在左。 |
7.堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
步骤:
- 创建最大堆:将堆所有数据重新排序,使其成为最大堆
- 最大堆调整:作用是保持最大堆的性质,是创建最大堆的核心子程序
- 堆排序:移除位在第一个数据的根节点,并做最大堆调整的递归运算
代码实现:
1 | # -*- coding:utf-8 -*- |
8.计数排序
1 | # -*- coding:utf-8 -*- |
