RabbitMQ
RabbitMQ 是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开源实现,由以高性能、健壮以及可伸缩性出名的 Erlang 写成,因此也是继承了这些优点
很成熟,久经考验,应用广泛
文档详细,客户端丰富,几乎常用语言都有RabbitMQ的开发库
安装
http://www.rabbitmq.com/install-rpm.html
选择RPM包下载,选择对应平台,本次安装在CentOS 7,其它平台类似
由于使用了erlang语言开发,所以需要erlang的包。erlang和RabbitMQ的兼容性,参考 https://www.rabbitmq.com/which-erlang.html#compatibility-matrix
下载 rabbitmq-server-3.7.16-1.el7.noarch.rpm、erlang-21.3.8.6-1.el7.x86_64.rpm。socat在CentOS中源中有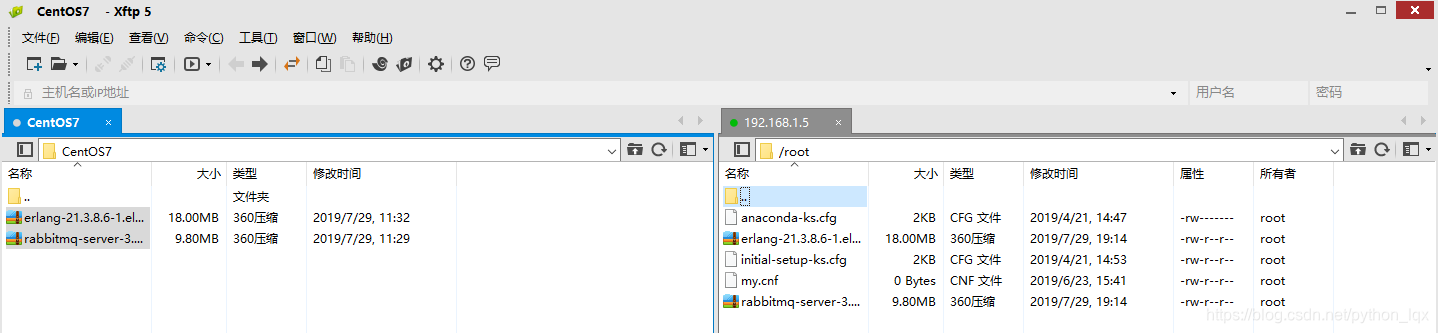
1
# yum install erlang-21.3.8.6-1.el7.x86_64.rpm rabbitmq-server-3.7.16-1.el7.noarch.rpm
安装成功
查看安装的文件1
2
3
4
5
6
7
8
9
10
11
12
13# rpm -ql rabbitmq-server
/etc/profile.d/rabbitmqctl-autocomplete.sh
/etc/rabbitmq
/usr/lib/rabbitmq/bin/rabbitmq-plugins
/usr/lib/rabbitmq/bin/rabbitmq-server
/usr/lib/systemd/system/rabbitmq-server.service
/usr/sbin/rabbitmq-diagnostics
/usr/sbin/rabbitmq-plugins
/usr/sbin/rabbitmq-server
/usr/sbin/rabbitmqctl
/var/lib/rabbitmq
/var/lib/rabbitmq/mnesia
/var/log/rabbitmq
配置
http://www.rabbitmq.com/configure.html#config-location
环境变量
使用系统环境变量,如果没有使用rabbitmq-env.conf 中定义环境变量,否则使用缺省值
RABBITMQ_NODE_IP_ADDRESS the empty string, meaning that it should bind to all network interfaces.
RABBITMQ_NODE_PORT 5672
RABBITMQ_DIST_PORT RABBITMQ_NODE_PORT + 20000 内部节点和客户端工具通信用
RABBITMQ_CONFIG_FILE 配置文件路径默认为/etc/rabbitmq/rabbitmq
环境变量文件,可以不配置
工作特性配置文件
rabbitmq.config配置文件
3.7支持新旧两种配置文件格式
- erlang配置文件格式,为了兼容继续采用

- sysctl格式,如果不需要兼容,RabbitMQ鼓励使用

这个文件也可以不配置
插件管理
列出所有可用插件1
# rabbitmq-plugins list
启动WEB管理插件,会依赖启用其它几个插件rabbitmq-plugins enable rabbitmq_management1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# rabbitmq-plugins enable rabbitmq_management
Enabling plugins on node rabbit@centos7:
rabbitmq_management
The following plugins have been configured:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@centos7...
The following plugins have been enabled:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
set 3 plugins.
Offline change; changes will take effect at broker restart.
启动rabbitmq服务
1 | # systemctl start rabbitmq-server |
启动中,可能出现下面的错误Error when reading /var/lib/rabbitmq/.erlang.cookie: eacces
就是这个文件的权限问题,修改属主、属组为rabbitmq即可chown rabbitmq.rabbitmq /var/lib/rabbitmq/.erlang.cookie: eacces
服务启动成功1
2
3
4# ss -tanl | grep 5672
LISTEN 0 128 *:25672 *:*
LISTEN 0 128 *:15672 *:*
LISTEN 0 128 :::5672 :::*
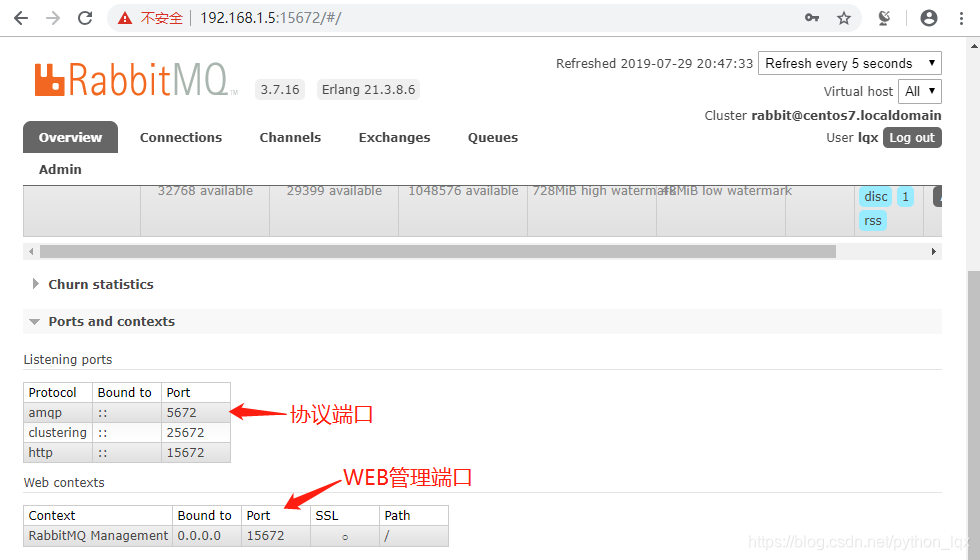
15672 http用的端口
25672 集群通信
5672 按协议访问,常用
用户管理
开始登录WEB界面,http://192.168.1.5:15672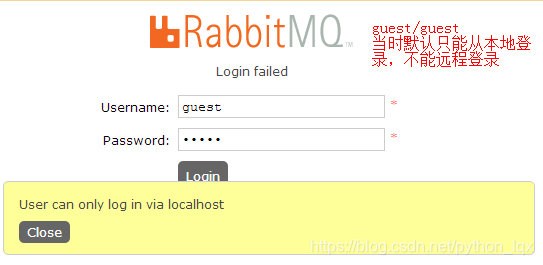
使用guest/guest只能本地地登录,远程登录会报错1
2
3
4
5
6
7
8
9
10
11
12
13
14
15rabbitmqctl [-n <node>][-t timeout] [-l][-q] <command> [<command options>]
General options:
-n node
-q, --quiet
-t,--timeout timeout
-l longnames
Commands:
add_user <username> <password> 添加用户
list_users 列出用户
delete_user username 删除用户
change_password <username> <password> 修改用户名、密码
set_user_tags <username> <tag> [...] 设置用户tag
list_user_permissions <username> 列出用户权限
创建用户 用户名和密码(只能在本地登录)
- 添加用户:
rabbitmqctl add_user username password - 删除用户:
rabbitmqctl delete_user username - 更改密码:
rabbitmqctl change_password username newpassword - 设置权限Tags,其实就是分配组
rabbitmqctl set_user_tags username tag
设置lqx用户为管理员tag后登录1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 创建lqx用户
# rabbitmqctl add_user lqx lqx
Adding user "lqx" ...
# 查看所有用户
# rabbitmqctl list_users
Listing users ...
user tags
guest [administrator]
lqx []
#授权用户权限
# rabbitmqctl set_user_tags lqx administrator
Setting tags for user "lqx" to [administrator] ...
# 查看所有用户
# rabbitmqctl list_users
Listing users ...
user tags
guest [administrator]
lqx [administrator]
tag的意义如下
administrator 可以管理用户、权限、虚拟主机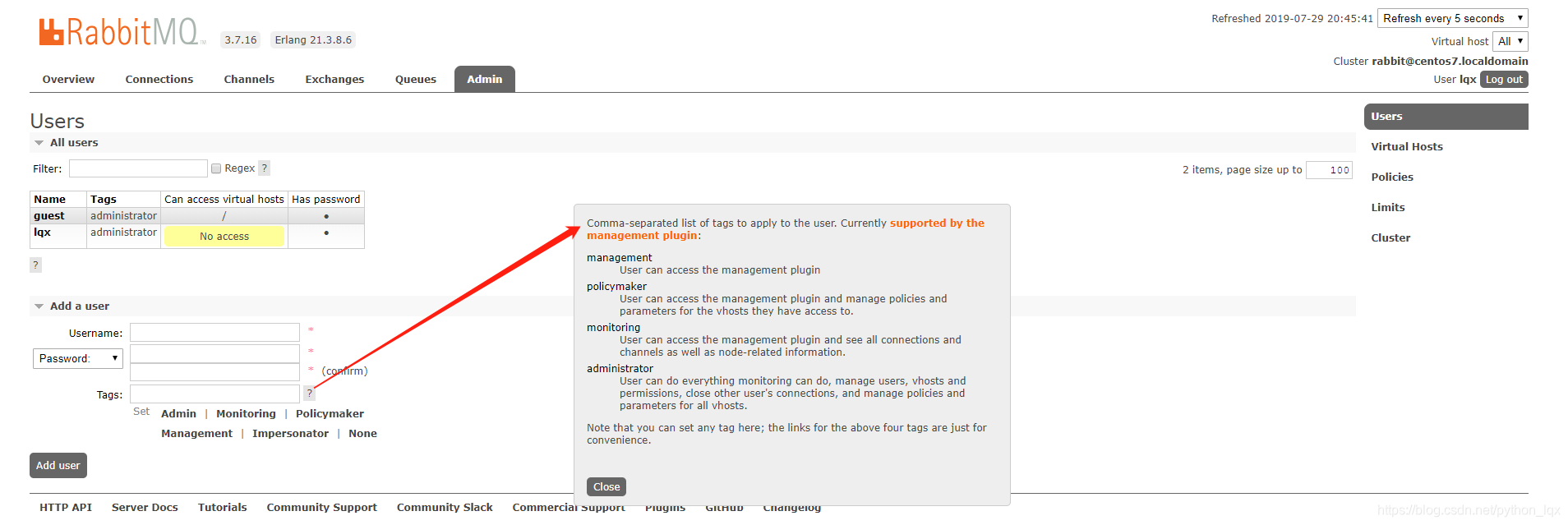
基本信息
虚拟主机

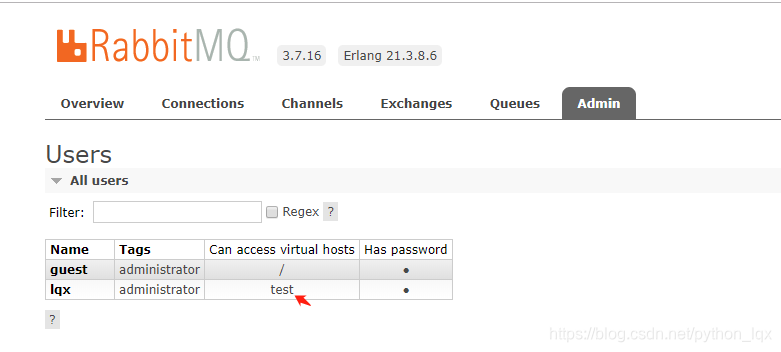
/为缺省虚拟主机
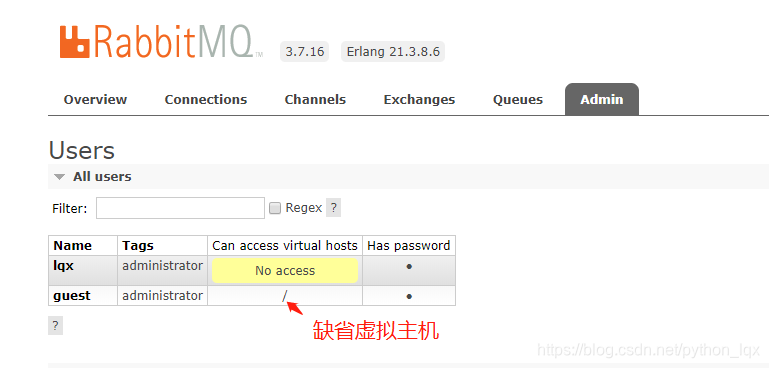
缺省虚拟主机,默认只能是guest用户在本机连接。上图新建的用户lqx默认无法访问任何虚拟主机
Pika库
Pika是纯Python实现的支持AMQP协议的库$ pip install pika
RabbitMQ工作原理及应用
工作模式
https://www.rabbitmq.com/getstarted.html
上图,列出了RabbitMQ的使用模式,学习上面的模式,对理解所有消息队列都很重要
名词解释
| 名词 | 说明 |
|---|---|
| Server | 服务器 接收客户端连接,实现消息队列及路由功能的进程(服务),也称为 消息代理 注意,客户端可以生产者,也可以是消费者,它们都需要连接到Server |
| Connection | 网络物理连接 |
| Channel | 一个连接允许多个客户端连接 |
| Exchange | 交换器。接收生产者发来的消息,决定如何路由给服务器中的队列 常用的类型有: direct (point-to-point) topic (publish-subscribe) fanout (multicast) |
| Message | 消息 |
| Message Queue |
消息队列 数据的存储载体 |
| Bind | 绑定 建立消息队列和交换器之间的关系,也就是说交换器拿到数据,把什么样的数据送给哪个队列 |
| Virtual Host | 虚拟主机 一批交换机、消息队列和相关对象的集合。为了多用户互不干扰,使用虚拟主机分组交换机、消息队列 |
| Topic | 主题、话题 |
| Broker | 可等价为Server |
先链接 然后信道,然后交换机(缺省默认配置), 然后队列
1. 队列
这种模式就是最简单的 生产者消费者模型,消息队列就是一个FIFO的队列
生产者send.py,消费者receive.py
官方例子 https://www.rabbitmq.com/tutorials/tutorial-one-python.html
参照官方例子,写一个程序1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import pika
params = pika.ConnectionParameters('192.168.1.5')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机, 路由器
# 队列
channel.queue_declare(queue='hello')
with connection:
# 发消息
msg = 'Hello World!'
channel.basic_publish(exchange='', # 交换机为空
routing_key='hello', # hello
body=msg)
print(" [x] Sent 'Hello World!'")
运行结果如下1
2pika.exceptions.ProbableAuthenticationError: ConnectionClosedByBroker: (403) 'ACCESS_REFUSED
- Login was refused using authentication mechanism PLAIN. For details see the broker logfile.'
访问被拒绝,还是权限问题,原因还是guest用户只能访问localhost上的 / 缺省虚拟主机
解决办法*
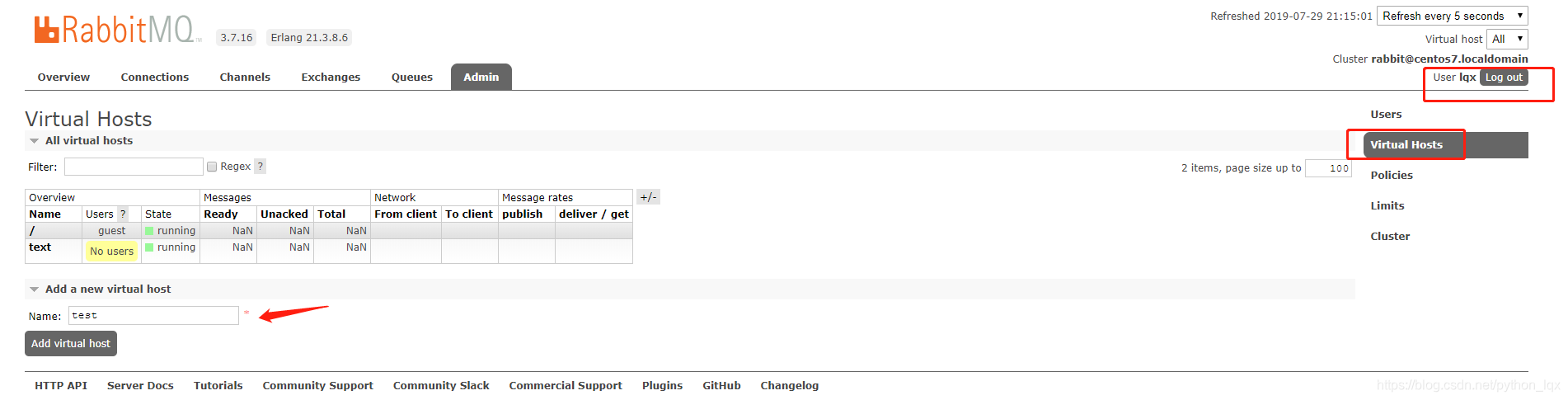
- 缺省虚拟主机,默认只能在本机访问,不要修改为远程访问,是安全的考虑
- 因此,在Admin中Virtual hosts中,新建一个虚拟主机test。
- 注意,新建的test虚拟主机的Users是谁,本次是lqx用户
生产者代码
1 | import pika |
消费者代码(get方法,非阻塞)
1 | import pika |
消费者代码(consume方法,阻塞)
1 | import pika |
执行结果1
2
3
4
5
6
7
8
9
10
11[*] Waiting for messages. To exit press CTRL+C
[x] Receivde b'data-00'
[x] Receivde b'data-01'
[x] Receivde b'data-02'
[x] Receivde b'data-03'
[x] Receivde b'data-04'
[x] Receivde b'data-05'
[x] Receivde b'data-06'
[x] Receivde b'data-07'
[x] Receivde b'data-08'
[x] Receivde b'data-09'
2. 工作队列

- 继续使用队列模式的生产者消费者代码
- 一个链接里启2个消费或者启动2个链接消费
- 结果都是一样的
生产者代码不变,修改消费者代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import pika
queue_name = 'hello'
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机, 路由器
# 队列
channel.queue_declare(queue=queue_name)
def callback(ch ,method, properties, body):
print("mag = {}".format(body))
def callback1(ch ,method, properties, body):
print("mag1 = {}".format(body))
with connection:
# 消费者,每一个消费者使用过一个basic_consume
channel.basic_consume(queue_name,
auto_ack=True,
on_message_callback=callback)
channel.basic_consume(queue_name,
auto_ack=True,
on_message_callback=callback1)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 启动所有消费,直到所有消费结束,才能退出。阻塞的
执行结果1
2
3
4
5
6
7
8
9
10
11 [*] Waiting for messages. To exit press CTRL+C
mag = b'data-00'
mag1 = b'data-01'
mag = b'data-02'
mag1 = b'data-03'
mag = b'data-04'
mag1 = b'data-05'
mag = b'data-06'
mag1 = b'data-07'
mag = b'data-08'
mag1 = b'data-09'
- 这种工作模式是一种竞争工作方式,对某一个消息来说,只能有一个消费者拿走它
- 从结果知道,使用的是轮询方式拿走数据的
- 观察结果,可以看到,2个消费者是交替拿到不同的消息
注意:虽然上面的图中没有画出exchange,用到缺省exchange
3. 发布、订阅模式(扇出)
Publish/Subscribe发布和订阅,想象一下订阅报纸,所有订阅者(消费者)订阅这个报纸(消息),都应该拿到一份同样内容的报纸
订阅者和消费者之间还有一个exchange,可以想象成邮局,消费者去邮局订阅报纸,报社发报纸到邮局,邮局决定如何投递到消费者手中
上例中工作队列模式的使用,相当于,每个人只能拿到不同的报纸。所以,不适用发布订阅模式

当前模式的exchange的type是fanout,就是一对多,即广播模式。
注意,同一个queue的消息只能被消费一次,所以,这里使用了多个queue,相当于为了保证不同的消费者拿到同
样的数据,每一个消费者都应该有自己的queue
1 | # 生成一个交换机 |
生产者使用广播模式。在test虚拟主机主机下构建了一个logs交换机
至于queue,可以由生产者创建,也可以由消费者创建
本次采用使用消费者端创建,生产者把数据发往交换机logs,采用了fanout,然后将数据通过交换机发往已经绑定到此交换机的所有queue
绑定Bingding,建立exchange和queue之间的联系
生产者代码(交换机缺省模式)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import pika
queue_name = 'hello'
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机, 路由器
channel.exchange_declare(exchange='',
exchange_type='direct')
# 队列
channel.queue_declare(queue=queue_name)
with connection:
# 发消息
for i in range(10):
msg = 'data-{:02}'.format(i)
channel.basic_publish(exchange='', # 交换机为空
routing_key=queue_name, # hello
body=msg)
print(" [x] Sent 'Hello World!'")
生产者代码(指定交换机)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import pika
queue_name = 'hello'
exchange_name = 'logs'
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机, 路由器
channel.exchange_declare(exchange=exchange_name,
exchange_type='fanout') # 广播,扇出
with connection:
# 发消息
for i in range(10):
msg = 'data-{:02}'.format(i)
channel.basic_publish(exchange=exchange_name, # 指定交换机
routing_key='',
body=msg)
print(" [x] Sent 'Hello World!'")
消费者代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import pika
queue_name = 'hello'
exchange_name = 'logs'
params = pika.URLParameters('amqp://lqx:lqx@192.168.18.100:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机, 路由器
channel.exchange_declare(exchange=exchange_name,
exchange_type='fanout') # 广播,扇出
with connection:
# 发消息
for i in range(10):
msg = 'data-{:02}'.format(i)
channel.basic_publish(exchange=exchange_name, # 指定交换机
routing_key='',
body=msg)
print(" [x] Sent 'Hello World!'")
先启动消费者可以看到已经创建了exchange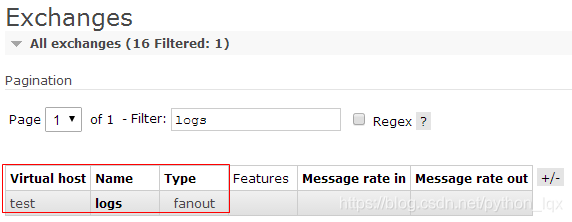
如果exchange是fanout,也就是广播了,routing_key就无所谓是什么了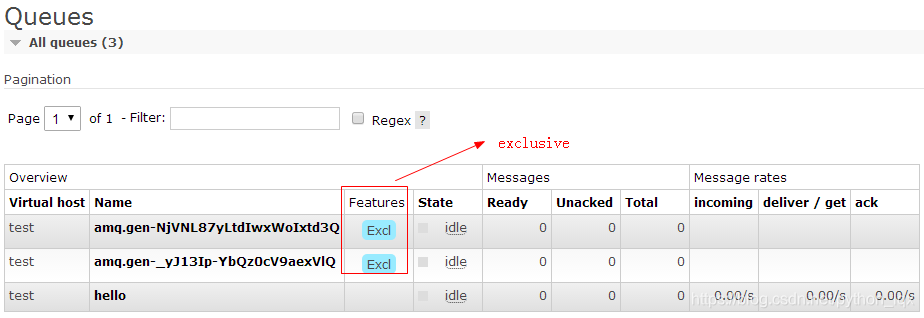
1
2q1 = channel.queue_declare(queue='', exclusive=True)
q2 = channel.queue_declare(queue='', exclusive=True)
尝试先启动生产者,再启动消费者试试看。
部分数据丢失,因为,exchange收到了数据,没有queue接收,所以,exchange丢弃了这些数据
4.路由Routing

路由其实就是生成者的数据经过exchange的时候,通过匹配规则,决定数据的去向
生产者代码
交换机类型为direct,指定路由的keyn1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import pika
import pika
import random
queue_name = 'hello'
exchange_name = 'color'
colors = ('orange', 'red', 'green')
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
#交换机, 路由器
channel.exchange_declare(exchange=exchange_name,
exchange_type='direct') #
with connection:
# 发消息
for i in range(20):
rk = random.choice(colors)
msg = '{}: data-{:02}'.format(rk, i)
channel.basic_publish(exchange=exchange_name, # 指定交换机
routing_key=rk,
body=msg)
print(" [x] Sent 'Hello World!'")
消费者代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40import pika
queue_name = 'hello'
exchange_name = 'color'
colors = ('orange', 'black', 'green')
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
#交换机,路由器
channel.exchange_declare(exchange=exchange_name,exchange_type='direct')
# 队列
#channel.queue_declare(queue=queue_name)
#q = channel.queue_declare(queue='') 不指定名称,queue名称会随机生成 q.method.queue
q1 = channel.queue_declare(queue='', exclusive=True) #exclusive 在断开时,会queue删除
q2 = channel.queue_declare(queue='', exclusive=True) #exclusive 在断开时,会queue删除
q1name = q1.method.queue
q2name = q2.method.queue
channel.queue_bind(exchange=exchange_name, queue=q1name, routing_key=colors[0]) # 将队列和某一个交换机关联
channel.queue_bind(exchange=exchange_name, queue=q2name, routing_key=colors[1]) # 将队列和某一个交换机关联
channel.queue_bind(exchange=exchange_name, queue=q2name, routing_key=colors[2]) # 将队列和某一个交换机关联
def callback(ch, method, properties, body):
print("msg = {}".format(body), method)
with connection:
# 消费者,每一个消费者使用一个basic_consume
channel.basic_consume(queue=q1name,
auto_ack=True,
on_message_callback=callback)
channel.basic_consume(queue=q2name,
auto_ack=True,
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 启动所有消费,直到道所有消费结束,才能退出,阻塞的
绑定结果如下
如果routing_key设置的都一样,会怎么样?

绑定的时候指定的routing_key='black',如上图,和fanout就类似了,都是1对多,但是不同
因为fanout时,exchange不做数据过滤的,1个消息,所有绑定的queue都会拿到一个副本
direct时候,要按照routing_key分配数据,上图的black有2个queue设置了,就会把1个消息分发给这2个queue
5、Topic 话题

Topic就是更加高级的路由,支持模式匹配而已
Topic的routing_key必须使用 . 点号分割的单词组成。最多255个字节
支持使用通配符:
*表示严格的一个单词#表示0个或者多个单词
如果queue绑定的routing_key只是一个#,这个queue其实可以接收所有的消息
如果没有使用任何通配符,效果类似于direct,因为只能和字符匹配
生产者代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import pika
import random
queue_name = 'hello'
exchange_name = 'color'
topics = ('phone.*', '*.red') # * 一个单词
products = ('phone', 'pc', 'tv')
colors = ('orange', 'black', 'red')
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机,路由器
channel.exchange_declare(exchange=exchange_name,
exchange_type='topic') # 话题
with connection:
# 发消息
for i in range(20):
rk = random.choice(colors)
msg = '{}: data-{:02}'.format(rk, i)
channel.basic_publish(exchange=exchange_name, # 指定交换机
routing_key=rk,
body=msg)
print('-' * 30)
print(" [x] Sent 'Hello World!'")
消费者代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import pika
queue_name = 'hello'
exchange_name = 'color'
topics = ('phone.*', '*.red') # * 一个单词
products = ('phone', 'pc', 'tv')
colors = ('orange', 'black', 'red')
params = pika.URLParameters('amqp://lqx:lqx@192.168.1.5:5672/test')
connection = pika.BlockingConnection(params)
channel = connection.channel()
# 交换机,路由器
channel.exchange_declare(exchange=exchange_name,
exchange_type='topic') # 话题
# 队列
#channel.queue_declare(queue=queue_name)
#q = channel.queue_declare(queue='') 不指定名称,queue名称会随机生成 q.method.queue
q1 = channel.queue_declare(queue='', exclusive=True) #exclusive 在断开时,会queue删除
q2 = channel.queue_declare(queue='', exclusive=True) #exclusive 在断开时,会queue删除
q1name = q1.method.queue
q2name = q2.method.queue
channel.queue_bind(exchange=exchange_name, queue=q1name, routing_key=colors[0]) # 将队列和某一个交换机关联
channel.queue_bind(exchange=exchange_name, queue=q2name, routing_key=colors[1]) # 将队列和某一个交换机关联
def callback(ch, method, properties, body):
print("msg = {}".format(body), method)
with connection:
# 消费者,每一个消费者使用一个basic_consume
channel.basic_consume(queue=q1name,
auto_ack=True,
on_message_callback=callback)
channel.basic_consume(queue=q2name,
auto_ack=True,
on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 启动所有消费,直到道所有消费结束,才能退出,阻塞的

观察消费者拿到的数据,注意观察 phone.red 的数据出现的次数
由此,可以知道 交换机在路由消息的时候,只要和queue的routing_key匹配,就把消息发给该queue
RPC 远程过程调用
RabbitMQ的RPC的应用场景较少,因为有更好的RPC通信框架
消息队列的作用
- 系统间解耦
- 解决生产者、消费者速度匹配
由于稍微上规模的项目都会分层、分模块开发,模块间或系统间尽量不要直接耦合,需要开放公共接口提供给别的模块或系统调用,而调用可能触发并发问题,为了缓冲和解耦,往往采用中间件技术
RabbitMQ只是消息中间件中的一种应用程序,也是较常用的消息中间件服务
